未来已来,随着科技的不断发展,交互的方式也发生巨大的变化,它正一步步颠覆着我们的生活习惯。


来让我们一起看看费茨定律是个啥?
百度all in AI之后,前天发布了无人驾驶的Apollo(阿波罗)系统,随着李彦宏被堵在五环的消息刷遍朋友圈,互联网圈好像一夜之间好像都在对未来的无人驾驶充满遐想。
尤瓦尔·赫拉利在《未来简史》中令人最眼前一亮的就是信数据得永生的概念,在数据积累到2016这个节点之后。仿佛什么东西如果不粘上大数据、智能算法和AI你都不好意思写BP。
进入今天交互闲谈的主题,在很多展现未来科技的电影和美剧中,我其实有着重留意他们对于未来设备的交互方式。不同的导演为我们展现了各自心目中对于未来人机交互的遐想,有双手多点交互,眼动追踪交互,语音识别交互等等。
有心人不禁会问,人机交互方式的发展到底是否有所据可依?在上一篇文章:《app中的交互手势和意符设计》中我阐述了关于屏幕上的交互方式的“据”,并且从长远来看,倘若在人类与未来科技交互未摆脱『界面』这个范畴的话,那交互方式仍然绕不开触控。
在这里引入一个交互设计定律:费兹定律(Fitts’ Law)
费兹定律(Fitts’ Law)是心理学家 Paul Fitts 所提出的人机介面设计法则,是一种主要用于人机交互中的人类运动的预测模型。它主要定义了游标移动到目标之间的距离、目标物的大小和所花费的时间之间的关系。
定律的表达式如下图:
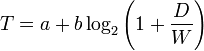
解释之前需要事先明确,费兹定律这个公式描述的是PC端鼠标点击事件的操作花费时间,虽然如此,但其实他对app中手势交互和意符设计有深远的影响,同时也对于未来科技的交互方式的推测起着指引作用。
关于这个公式的推演和发展比较复杂,我尝试追本溯源的探索了一下这个公式最初的的推演,在这里就不多做介绍,有兴趣的可以去认真阅读Wikipedia中的相关定义,在这里只做最基本的科普性解释:
回到公式本身,其中:
MT 代表平均完成这次操作所花费的时间,a和b是一个取决于输入设备选择的常数, a代表系统一定会花费的时间(理想耗时),b 是系统速率(不同设备的a和b大抵也是正态离散分布在一条函数上,大家只需要了解a和b是一个常数就行了),ID是负责度指数,他的值是后面这个log函数;log里面的D是指从光标(指示位置)与目标中心的距离,W指的是点击目标宽度,同时W也是容许用户犯错的最后边界。

如上图所示,解释一下,就是如果光标现在在任易地点想要去点击目标target,最短路径一定是D,最短路径上容错的最长路径是D+W,只要水平上移动超过了D+W你就点不到了,而这个点击动作所耗的时间是一个常数加上一个以D为正比W为反比的函数的和。
上面没读懂就算了,主要看结论,那费兹定律这能给到我们什么启示呢?
结论:目标越大,完成点击越快,时间越短。同样地,目标越近,指向越快,完成点击时间越短。也就是说,定位点击一个目标的时间,取决于目标与当前位置的距离,以及目标的大小(在特定场景下,当然还会有其他因素,但这并不在我们今天的讨论范畴)。
关于费兹定律在PC端网页设计和app设计中的应用,在这里我就不多说了,网上大把大把这样的文章,我主要想谈的是费兹定律对于未来交互方式的影响。
在可以预期的未来,当科技发展到不是物理屏幕,而是光投屏或者别的方式的时候。

可以预言的是,只要屏幕智能达不到脑控或者眼控,其满足的交互方式一定是:
1.多点触控 + 手势感应 + 眼控识别
先说说多点触控,大家印象最深的多点触控其实是pinch操作,双指放大缩小一张图片。其次就是ipad上多指向上推启动任务后台管理器,这个功能其实和iphone里面双击home键是一样的,但是由于ipad屏幕比较大,所以额外引入了这种交互方式。
前几天和几个交互小伙伴喝茶聊天,我们一致的观点都认为其实现在手机端的交互手势是已经很固定了,而且点击啊,滑动啊这些交互手势其内在的用户心理预期也基本成熟,如果需要在交互方式上有大的创新,大概就需要等到下一轮科技的刺激,或者等到无屏幕的时代。
多点操控其实在很多关乎未来的电影里面都有描述,比如远程操控一个无人驾驶的飞机,比如操作一个更加复杂的数据工作台。
这些未来一定会出现的更加复杂的交互方式,一定也会受到传统交互手势和交互定律的启示,比如这个交互:

将流媒体变为上下两轨,每一个时间段展示一个帧截图,屏幕尽头是无限延伸的轨道,这时候如果要设计滑动整个轨道的交互方式,一定是五指触碰然后滑动。
那比如我们需要设计一个非线编的交互方式,使得第一屏的视频A放到第五屏的视频B前面,那这时候需要做的大概是长按拎起视频A,然后另一只手五指滑动轨道到第五屏,再把视频A拎到B前面,而这里采用的就是通过五指滑动这一个手势,减小了费兹定律表达式中的D,从而使得这个操作时间更快。
其他的例子其实还有很多,大家多留心身边的科幻电影中的交互就好。
关于眼控识别,我能想到的脑洞是用于定位和拖拽交互。比如还是上面的那个例子,如果引入眼控的话,大概流程是长按拎起视频A,然后眨三下眼让系统识别你开启眼控拖拽,然后你看着第一屏的信息,通过眼动快速滑到第五屏,再把视频A拎到B前面,完成整个交互,然后再眨巴三下眼,系统识别到关闭眼控拖拽。
关于其他的未来交互方式,语音交互一定也算在其中。
2.VUI(Voice User Interface)
上周我去参加了IxDC,听了一场关于VUI的专题演讲,这个概念其实自从电影《Her》出来之后就越来越受到交互设计师的关注。
其实与其说是Interface,我倒觉得这个Interface应该写作Interaction(交互协作)更为恰当,大家看电影《Her》中,或者去看《星际迷航》、《星际穿越》、《生化危机》中,他们操纵大型设备更多的时候是靠语音直接输入指令的。这样做当然更加高效便利,他甚至已经超出了触控交互,不在墨菲定理所能起作用的范畴之内。
但是脑洞一开,VUI其实需要很成熟的语音识别反馈技术,如果技术尚未成熟,那就需要花费大量的用户教育成本才可以大力推行。
我曾经理想的点外卖场景是打开一个app,它传来磁性的妹子声音问你现在想要吃点啥?然后我说我也不清楚,但是想吃辣,然后她说给你推荐了人气最高的酸辣鱼,冒菜和麻辣香锅,然后我说行就酸菜鱼吧,40块钱以内直接下单,要快。于是整个流程结束。或者它报出的没有我想吃的,然后我说你把附近最火的辣的东西列出来我看看,然后马上屏幕上出现分好类的item列表,我再手动选择也可以。
让我们来期待这一天。
3.脑控一切
这个就牛逼了,简直就是上帝啊,在这里就不做过多讨论。
写在最后
为什么要和大家讨论未来交互方式呢?
用一句文艺的话来说叫做:『未来已来。』
不管大家信不信,我是坚信最多不超过5年,第一代手机的替代产品就会问世(也许现在已经问世了只是我们还不知道)。它可能是一个眼睛,一支笔,或者一个别的什么鬼我们现在只能有一个方向但是并不能窥其具体的物件。
但是未来不论科技如何发展,总是会有交互设计师更广阔的空间的,想想未来茫茫多的智能硬件,每一个智能硬件的交互都千差万别,我们如何做到像手机发展到今天那样的交互形式统一。想想未来还有那么多新鲜玩意儿的交互需要去制定,想想我们可以让未来生活在设计中更加智能和更加易用。
想想就开心。
本文由@Seany. 原创发布于人人都是产品经理,未经许可,禁止转载。
原创文章,作者:Catherine,如若转载,请注明出处:https://www.iamue.com/21225/

