
Facebook 现在在信息推荐、过滤攻击言论、推荐热门话题、搜索结果排名等等已经使用了大量人工智能和深度学习的技术。在Facebook上,还有许多试验能够从机器学习模型中获利,但是目前,对于很多没有深厚机器学习背景的工程师来说,想要利用这些机器学习基础设施,还是有很大的困难。2014年年末Facebook发布FBLearner Flow,决定重新定义自己的机器学习平台,把人工智能与机器学习中最先进的算法以最便利的方式提供给Facebook的工程师。
在早期运用人工智能与机器学习的试验中,Facebook 发现,准确度上最大的提升往往来自快速的试验、功能编程和模式调试,而非从根本上运用不同的算法。此前,在找到成功的新功能,或者一个超参数集时,工程师可能需要进行上千次试验。Facebook对传统的流水线系统进行评估发现,这一系统并没有很好的匹配Facebook的需求,大多数的解决方案并没有提供以不同的输入来重新运行这一流水线的解决方案;也没有提供机制来具体地分析产出和副作用;没有提供对输出的可视化;没有为参数扫描之类的任务提供条件步骤。
为了实现这些点,Facebook想要一个具备以下属性的平台:
- 每一种机器算法都必须以一种可再使用的方式运行过一次。
- 工程师应该能写出一个训练流水线,这些流水线可以在多种机器中平行切换,并被其他工程师再使用。
- 对于具有不同机器学习经验的工程师来说,训练模型应该变得简便,并且,几乎每一步都应该是完全自动化的。
- 人人都应该能够便利地搜索过去的试验和测试结果,并与其他人分享,并在特定的试验中尝试新的变量。
所以Facebook决定建立一个全新的平台——FBLearner Flow。这一平台要能方便地在不同的产品中重复使用多种算法,并可以延伸到成千上万种模拟的定制试验操中,轻松地对实验进行管理。这一平台提供了创新性的功能,比如从流水线定义和对Python 编码进行自动化平行移用中自动生成用户界面(UI)试验。
目前,超过25%的Facebook工程开发团队都在使用FBLearner Flow。创建以来,该平台已经训练了超过100万模型。Facebook的预测服务,已经发展到每秒产生超过600万次预测。
在编码上减少人工劳动,要求进行一系列的试验,允许机器工程师把更多的时间花在功能编码上,这反过来能够让准确度得到更大的提升,进而,工程师能够产生更大范围的影响,现在的workflow写作者有150个左右,他们的工作的影响力已经超越了他们自己和团队。
核心概念和组成部分
在近距离地接触这一系统前,有几个关键的概念需要理解:
工作流(Workflow):一个工作流是限于FBLearner Flow中的一个流水线,并且是其所运行的有机器学习任务的入口。每一个Workflow负责的都是一个具体的任务,比如训练和评估具体的模型。Workflows由计算符系统的术语进行定义,可以被移用。
计算符(Operator):计算符是workflows的建造模块。从概念上,你可以把计算符认为是一个程序里面的一种功能。在FBLearner Flow中,计算符是单个机器中运行和执行的最小组件。
通道(Channels):通道代表作输入和输出。输入和输出在工作流和计算符之间的流动。所有的通道都是由Facebook定义的归类系统进行归类。
这一平台由三个核心部件组成:一个定制的分布式工作流的写作和执行环境;一个用户界面试验管理,用于发布试验和检查结果;还有许多事前定义的流水线,用于训练在Facebook最常见的使用机器学习的算法。
写作和执行环境
FBLearner Flow 中所有的工作流和计算符都被定义为Python中的函数,并使用特殊的修饰器,来与平台进行融合。来看一个简单的场景,假设我们想要根据经典的鸢尾花数据集训练一个决策树,以根据花的花瓣和花萼来预言花的种类。假设我们可用的数据集是在蜂巢(Hive)矩阵中,并且有5列,每一列分贝代表了花瓣宽度、花瓣长度、花萼宽度、花萼长度以及样本种类。在这个Workflow中,我们将会以对数损失(log loss)的方法来评估模型的表现,并且预测一个未加标签数据集的种类。
一个要处理的样本工作流可能会是这样的:
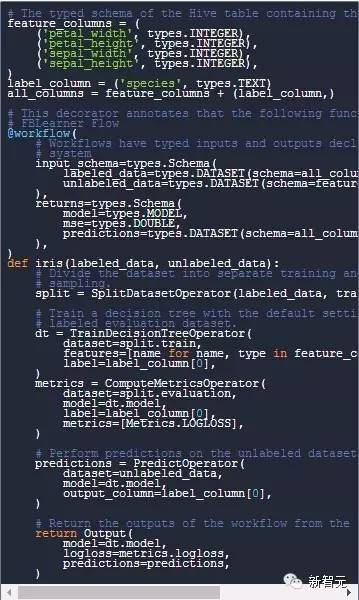
让我们更深入地查看这一工作流,以理解FBLearner Flow是如何工作的。
首先,工作流的修饰器会告诉FBLearner Flow,鸢尾花函数不是一个常见的Python函数,而是一个工作流。
输入图式和返回参数表明了工作流所期待的输入和输出类型。执行框架将自动地在运行时间内核实这些类型,并且强制Workflow接收它所期待的数据。参照下面的例子,输入的带标签数据被标注为一个数据集,并以分四列输入。如果在所提供的数据集中,其中一列缺失,系统会提出输入错误的警告,因为这一数据集与工作流是不相符的。
工作流的架构看起来像一个常规的Python函数,可以调用若干计算符,这些计算符执行的是真正的机器学习工作。虽然看起来很普通,但是FBLearner Flow采用了一个预测系统(system of future),在工作流内实现平行化迁移,让没有共享数据属性的步骤也可以同时运行。
Workflows的运行并不是连续性的,它分为两个部分:1,DAG编译部分;2,计算符执行部分。在DAG编译部分,工作流的计算符并不实际执行任务,而是反馈Futures。Futures指的是代表了计算延时模块的东西。所以在上文的例子中,dt变量其实是一个furure,它代表还没有发生的决策树训练。在DAG编译部分,FB Learner Flow记录了所有操作中的调用,还有一系列在进行操作开始前的futures。
比如,ComputeMetricsOperator和PredictOperator都把dt.model作为输入,这样以来,系统就知道,在操作运行前,nn必须要被计算,所以他们必须等待,直到 TrainDecisionTreeOperator完成。
完成了DAG编译部分后,FB Learner Flow就建立一个DAG 计算符,在这个计算符中,边界代表了数据的依赖性。这一个DAG随后能够被列入执行计划,在这儿,一旦它的父程序完全成功,计算符就能够开始执行。在这个例子中, ComputeMetricsOperator 和 PredictOperator的调用之间,不存在数据依赖性,所以这两个计算符的运行能够平行切换。
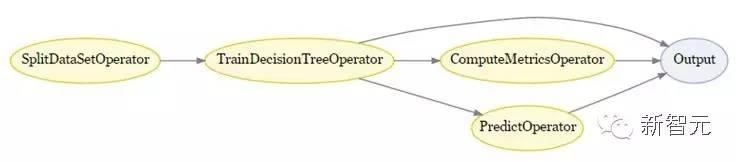
在计算符执行部分,每一个计算符在它的依赖计算符完成后,就开始运行。每一个计算符都有自己对CPU、GPU和内存要求,并且,FBLearner Flow将会分配机器的一部分,与计算符对任务的要求相匹配。FBLearner Flow 自动地处理,分配相关编码给机器,在输入和输出之间进行切换。
用户界面试验管理
在Facebook中,有好几百个不同的工作流,在执行无数的机器学习任务。Facebook面临的一个挑战是建立一个通用的UI,能够与Facebook的工程师所使用的一系列工作流共同工作。使用通用的类型系统,可以建立一个UI,能以一个不了解工作流的方式阐释输入和输出,也就是不需要理解每一个工作流实施的细节。对于未来的定制化,FBLearner Flow用户界面提供了一个插件系统,能够被不用的团队尝试定制化体验,并且融入Facebook的系统中。
FBLearner Flow UI提供一些额外的体验:1)发布工作流 2)对结果进行可视化和比较3)管理试验。
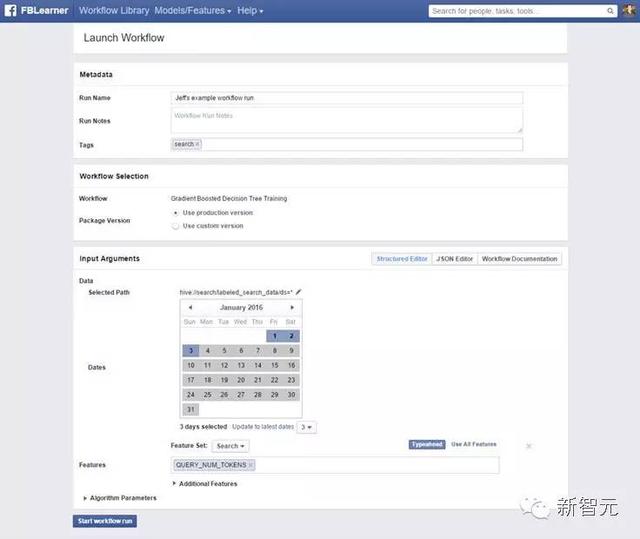
发布工作流
此前,Facebook曾发现,每一个工作流都要求一个类型输入图式。工程师发布一个工作流时,UI能够读到这个输入图式,并自动地生成架构表格,并且把具体的输入与工作流进行匹配。这允许机器学习工程师在一行前端代码都不用写的情况下,能够为他们的工作流获得丰富的UI。这将能让UI渲染复杂的输入要素,比如为分类和选择数据集。
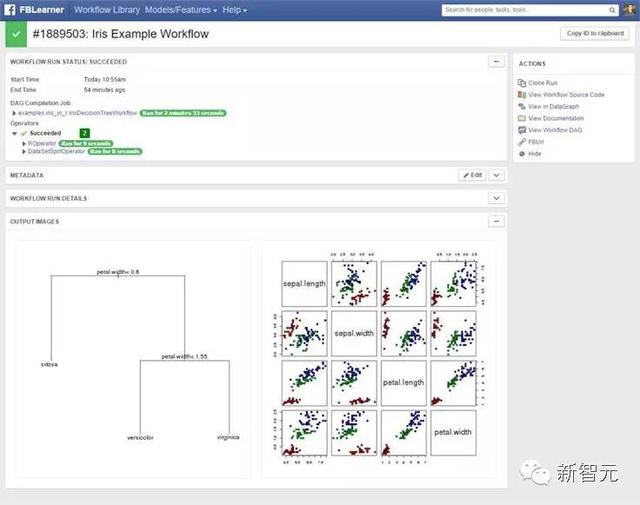
输出的可视化和比较
在用户界面上,工程师能够检查每一个工作流,观察输出,以修改标签和其它的元数据,并采取行动,比如配置模型,进行生产。Workflow中输入和输出可以进行对比,让工程师根据基线评价试验的表现。Facebook把对输出进行可视化的技术用于渲染输入,也就是用于提供具体类别,对每一个输出进行渲染的分类系统。
管理试验
Facebook的工程师每天要进行几千次试验,FBLearner Flow UI提供了管理这些试验的工具。所有的workflow都在Elasticsearch中编了索引,所以可以通过多种维度搜到,并且,系统的支持把搜索词条存到更容易被发现的试验中。在进行模式调试时,工程师经常会运行复杂的参数扫描,通过特定的渲染,可以看到哪一个基阵产生了最好的结果。
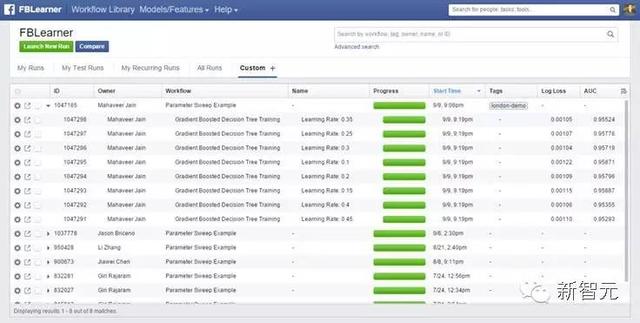
机器学习图书馆
FBLearner Flow平台的一个核心原则是,它不跟任何的算法进行捆绑。结果便是,平台能够支持大量的机器学习算法,以及结合了这些算法的创意。平台还很容易扩展,任何工程师都能写一个新的工作流来让整个公司的人都可以使用他或她最喜爱的算法。开放资源应用的算法能够便利地在工作流中使用,并融入Facebook 的基础设施中。
Facebook的应用机器学习算法团队在运行那些提供普通使用的算法可以扩展化的Workflow,其中包括:
- 神经网络
- 梯度推进的决策树
- Lambda MART
- 随机梯度递减
- 逻辑回归
未来计划
有了FB Learner Flow,AI会变成编程团队的一个组成部分,并为Facebook的工程师提供通过简单的API调用,紧跟AI的发展潮流。Facebook一直努力地提升FBLearner Flow,来让工程师变得越来越有生产力,并在越来越多的产品中使用机器学习。这些改进包括:
效率:过去的四月,在一个包含了几千台机器群集里,运行了超过500000 工作流。其中一些试验要求大量的计算资源,需要花掉好几天才能完成。Facebook着眼于提升这些试验的运行效率,来保证平台在把执行延迟最小化的同时,满足不断增长的需求。Facebook正在围绕数据局部性寻找新的解决方案,用来源数据共置计算,并且,Facebook也正在提高对资源要求的理解,来尽可能地让更多的试验在每一个机器中都能进行。
速度:FBLearner Flow是一个每天能吸收万亿数据的系统,每天训练的模型超过几千个,不管是离线还是实时,随后,把这些模型用于生活预测的服务器。工程师和相关团队,即便是没有什么专业知识,也能建立和允许试验,以更熟练前所未有的速度把AI支持的产品部署生产。Facebook正在努力把工作流完成的周期最小化,让产品能从最新的数据中进行学习,允许工程是快速地进行多次试验。
机器学习的自动化:许多机器学习算法都有很多可有优化的超参数。在Facebook,许多模型的准确度1%的提升都能产生许多有意义的影响。所以,有了Flow,Facebook为大规模的参数扫描和其它的自动的机器学习功能建立支持,利用闲置的循环来进一步提高这些模型。在这一领域,Facebook会进行进一步的投资,在Facebook的多种产品中提升Facebook AI和机器学习的专业性。
在接下来的几个月里,Facebook将会对一些特定的系统和应于保持高度关注,这些系统和应用能够利用FBLearner Flow来给工程师提供条件,让他们便利的在产品中使用AI 和深度学习,同时,也可以为Facebook用户提供更加个性化的体验。
Facebook核心机器学习小组的负责人Hussein Mehanna在接受媒体采访时说,Facebook在Flow上除了发表学术论文,可以做的还很多,公司最后会把这一平台开源。
文章译自:https://code.facebook.com/posts/1072626246134461/introducing-fblearner-flow-facebook-s-ai-backbone/
原创文章,作者:ioued,如若转载,请注明出处:https://www.iamue.com/14550/



